A Brief History: Who Developed It? K-Means clustering was introduced in the 1950s by Stuart Lloyd for signal processing and later refined in the 1970s by James MacQueen for data analysis. Today, it is a cornerstone in machine learning clustering …

A Brief History: Who Developed It? K-Means clustering was introduced in the 1950s by Stuart Lloyd for signal processing and later refined in the 1970s by James MacQueen for data analysis. Today, it is a cornerstone in machine learning clustering …
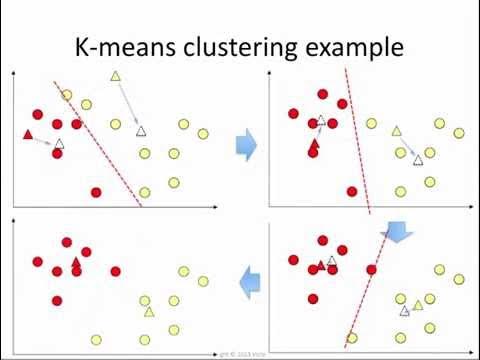
K-Means++, introduced in 2007, refines centroid placement in K-Means clustering for better accuracy and efficiency. Widely used in Australian public health, census analysis, and environmental insights, it ensures faster convergence and more reliable clusters.