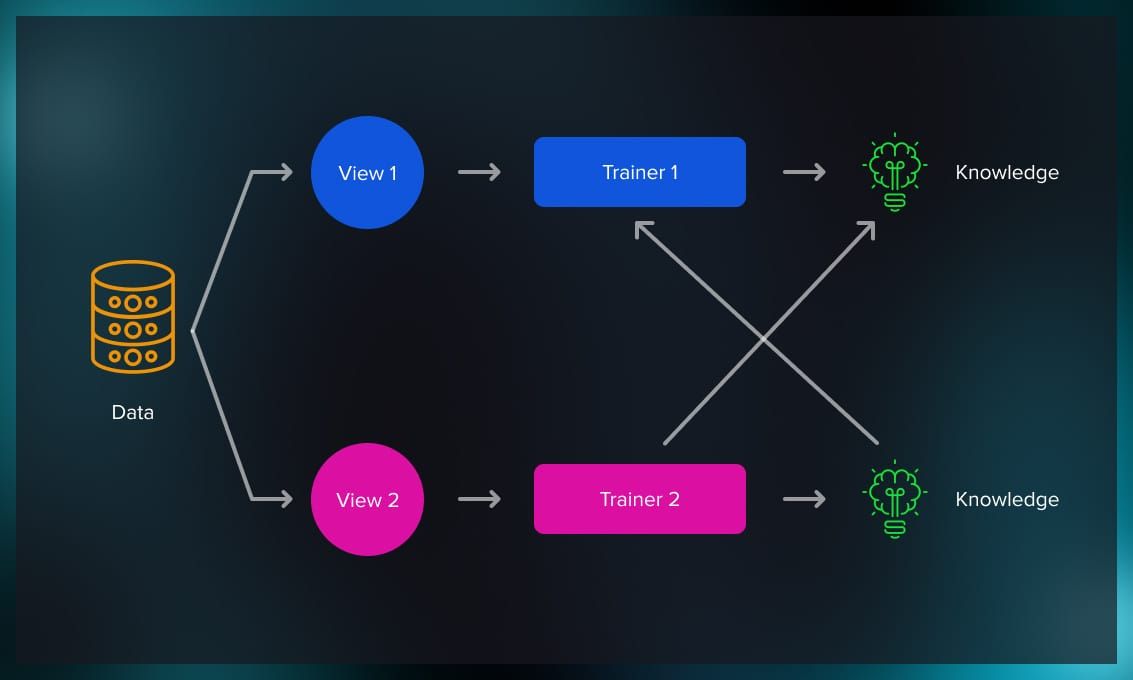
A Brief History: Who Developed Semi-Supervised Scenarios? The concept of semi-supervised learning (SSL) was introduced in the late 1990s to address the growing need to utilize unlabeled data in machine learning. Researchers like Xiaojin Zhu pioneered frameworks for combining labeled …