A Brief History: Who Developed the Cluster Assumption?
The cluster assumption, a foundational concept in semi-supervised learning (SSL), was introduced in the late 1990s. Researchers like Xiaojin Zhu and Avrim Blum formalized this principle, leveraging clustering and manifold learning theories to improve the efficiency of machine learning algorithms. Today, it is widely applied in tasks such as classification, clustering, and anomaly detection, particularly when labeled data is limited.
What Is the Cluster Assumption?
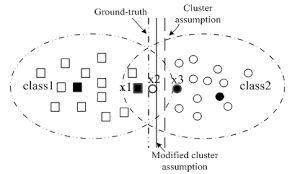
The cluster assumption posits that data points within the same cluster are likely to share the same label. It assumes natural groupings exist within data, guiding models to infer labels for unlabeled points.
Picture marbles rolling into bowls: each bowl naturally collects marbles based on their proximity and slope. Similarly, clusters represent natural groupings in data where points gravitate toward shared labels.

Why Is It Used? What Challenges Does It Address?
The cluster assumption resolves critical challenges in semi-supervised learning:
- Leveraging Unlabeled Data: Utilizes natural groupings in unlabeled datasets for more effective learning.
- Enhancing Accuracy: Assigns consistent labels to similar data points, improving prediction quality.
- Reducing Labeling Costs: Enables models to generalize effectively with fewer labeled examples.
Without this assumption, models may overlook hidden patterns in data, leading to inconsistent or inaccurate results.
How Is It Used?
- Data Preparation: Combine labeled and unlabeled datasets.
- Cluster Analysis: Use clustering algorithms like k-Means or DBSCAN to identify natural groupings in the data.
- Model Training: Train semi-supervised models to propagate labels to unlabeled points based on their cluster memberships.
Different Types of Cluster Assumptions
- Hard Clusters: Assign each data point to a single cluster with clear boundaries.
- Soft Clusters: Allow data points to belong to multiple clusters with probabilities.
Key Features
- Scalability: Processes large datasets efficiently using clustering techniques.
- Adaptability: Supports diverse machine learning tasks like classification, clustering, and regression.
- Robustness: Maintains performance by effectively utilizing both labeled and unlabeled data.
Software and Tools Supporting the Cluster Assumption
- Python Libraries:
- Scikit-learn: Provides algorithms like k-Means, DBSCAN, and Gaussian Mixture Models for clustering.
- TensorFlow and PyTorch: Enable custom implementations of cluster-based learning techniques.
- FastAI: Simplifies the integration of clustering methods into semi-supervised learning workflows.
- Platforms: Tools like Google Colab and Jupyter Notebooks allow interactive experimentation with clustering-based models.
3 Industry Application Examples in Australian Governmental Agencies
- Healthcare (Department of Health):
- Application: Identifying patient groups for personalized treatments.
- Use of Cluster Assumption: Groups patients based on similar symptoms to predict treatment outcomes efficiently.
- Environmental Management (Department of Agriculture, Water, and the Environment):
- Application: Classifying land use and ecosystems.
- Use of Cluster Assumption: Leverages natural groupings in biodiversity data to label ecosystem types.
- Public Policy (Australian Bureau of Statistics):
- Application: Analyzing demographic trends for policy-making.
- Use of Cluster Assumption: Clusters census data to uncover regional patterns and socio-economic trends.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!