A Brief History: Who Developed It?
Stochastic Gradient Descent (SGD) originated in the mid-20th century as an optimisation algorithm. Visionaries like Yann LeCun and Geoffrey Hinton refined its application, making it a cornerstone of machine learning and neural network training.
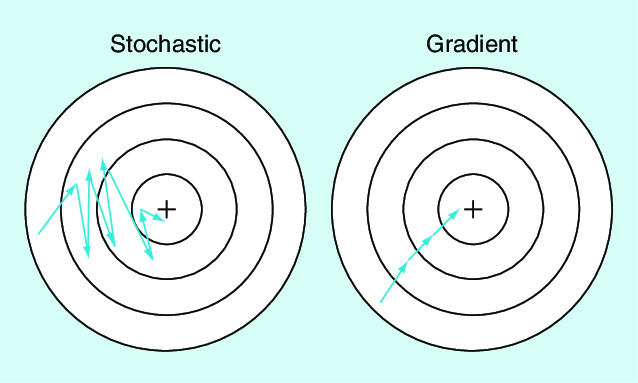
What Is Stochastic Gradient Descent?
SGD is a powerful optimisation algorithm that minimises error in machine learning models by processing smaller subsets of data. This approach ensures faster, more scalable training, especially for large datasets.
Why Is Stochastic Gradient Descent Used? What Problems Does It Solve?
SGD is indispensable in machine learning due to its ability to tackle critical challenges:
- Efficiency: Processes small batches for faster iterations.
- Scalability: Handles large datasets effectively without overwhelming system resources.
- Accuracy: Minimises overfitting in predictive models, enhancing reliability.
Challenges Solved:
- Accelerates model training for deep learning algorithms.
- Prevents memory overload when processing extensive datasets.
- Provides robustness in noisy datasets, ensuring stable performance.
How Does SGD Work?
SGD operates through an iterative process:
- Data Sampling: Mini-batches are drawn randomly from the dataset.
- Gradient Calculation: Computes error gradients for the selected batch.
- Weight Update: Incrementally adjusts model weights based on calculated gradients.
- Iteration: Repeats the process until convergence is achieved.
Imagine a hiker climbing a mountain in the dark with a flashlight. Instead of planning the entire route, they illuminate one small section at a time, making steady progress toward the peak.
Types of Stochastic Gradient Descent
SGD comes in various forms, tailored for different needs:
- Vanilla SGD: A basic approach with fixed learning rates.
- Mini-Batch SGD: Balances efficiency and stability by using small batches of data.
- Momentum SGD: Speeds up convergence by incorporating past gradients into updates.
- Nesterov Accelerated Gradient: Anticipates updates for smoother and faster convergence.
Key Features of SGD
SGD is renowned for its unique features:
- Dynamic Learning Rates: Adapts step sizes to ensure smooth convergence.
- Momentum Optimisation: Stabilises and accelerates weight updates.
- Regularisation: Minimises overfitting by applying penalty terms to model parameters.
Tools Supporting Stochastic Gradient Descent
SGD is widely supported by popular machine learning frameworks and libraries:
- TensorFlow: Advanced frameworks for implementing SGD in scalable projects.
- PyTorch: Flexible libraries ideal for customisation and experimentation.
- Keras: User-friendly tools for quick and efficient implementation.
- scikit-learn: Lightweight frameworks suited for small-scale projects.
Industry Applications of SGD in Australian Government
SGD drives innovation across various Australian industries:
- Healthcare Analytics:
- Application: Enhancing diagnostic tools and healthcare resource management.
- Urban Resource Planning:
- Application: Optimising public infrastructure allocation and urban development strategies.
- Climate Forecasting Models:
- Application: Improving weather prediction and environmental planning for sustainable resource management.
Conclusion
Stochastic Gradient Descent (SGD) is a transformative optimisation algorithm, enabling scalable and robust training for machine learning models. Its dynamic and efficient approach ensures its relevance in industries ranging from healthcare to urban planning. With versatile tools like TensorFlow and PyTorch, SGD remains an essential technique for solving modern data challenges.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!





