A Brief History: Who Developed It?
K-Means++ was introduced in 2007 by David Arthur and Sergei Vassilvitskii to address the shortcomings of traditional K-Means clustering. By refining the initialisation of centroids, K-Means++ significantly improved clustering accuracy and efficiency.
What Is K-Means++?
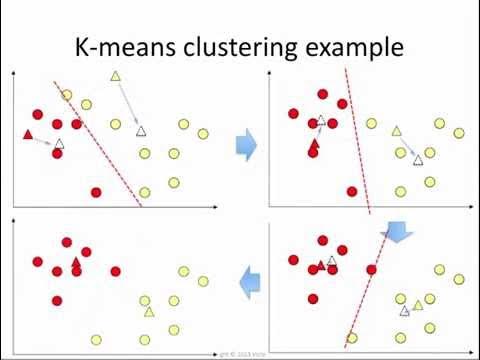
K-Means++ optimises the initialisation step of K-Means clustering by strategically selecting initial centroids. Imagine a treasure hunt where key points on the map are pre-marked, saving time and effort while ensuring the best results.

Why Is It Used? What Challenges Does It Address?
Purpose:
- Enhances Accuracy: Improves centroid placement, resulting in better clustering outcomes.
- Increases Efficiency: Reduces computational waste during the clustering process.
Challenges Addressed:
- Random Initialisation Issues: Poorly placed centroids often lead to suboptimal results and higher computational costs.
- Large and High-Dimensional Data: Tackles challenges in clustering complex datasets efficiently.
How Is K-Means++ Used?
The process of K-Means++ involves:
- Initial Centroid Selection: Randomly select the first centroid from the dataset.
- Distance Measurement: Calculate the distance between data points and the selected centroids.
- Probability-Based Selection: Select subsequent centroids based on the probability proportional to the square of the distance.
- Clustering: Run the K-Means algorithm to refine clusters iteratively.
This method ensures faster convergence and well-defined clusters.
Different Types of K-Means++
- Mini-Batch K-Means++:
- Processes data in chunks, making it ideal for large-scale datasets.
- Bisecting K-Means++:
- Combines hierarchical clustering with K-Means++ for more effective segmentation.
Key Features of K-Means++
- Strategic Initialisation: Reduces clustering errors caused by random centroid placement.
- High Efficiency: Performs effectively on large-scale datasets, ensuring faster convergence.
- Seamless Integration: Available in most modern machine learning frameworks.
Popular Software and Tools for K-Means++
K-Means++ is supported by numerous tools, making it accessible for developers and data scientists:
- Scikit-learn: Includes built-in functionality for Python-based clustering.
- Apache Spark MLlib: Optimised for distributed computing and big data tasks.
- R: Provides K-Means++ implementations for statistical clustering applications.
- MATLAB: Offers advanced clustering tools with visualisation support.
Applications of K-Means++ in Australian Governmental Agencies
K-Means++ plays a critical role in various Australian sectors:
- Public Health Analysis:
- Application: Identifies trends in patient health data to improve resource allocation and healthcare planning.
- Census Clustering:
- Application: Used by the Australian Bureau of Statistics to analyse demographic data for policy-making.
- Environmental Insights:
- Application: Geoscience Australia employs K-Means++ to segment geological and environmental datasets, aiding research and resource management.
Conclusion
K-Means++ refines the clustering process by addressing traditional K-Means limitations, ensuring more accurate and efficient outcomes. Its applications in public health, census analysis, and environmental monitoring demonstrate its versatility and importance. With robust support from tools like Scikit-learn and Apache Spark, K-Means++ remains a cornerstone for effective clustering in modern data science.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!