A Brief History of This Tool: Who Developed It?
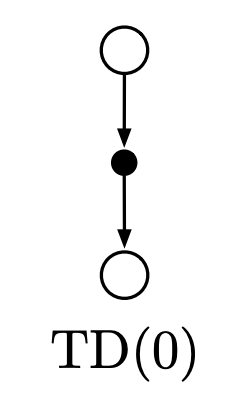
The TD(0) algorithm, short for Temporal Difference learning, was introduced by Richard Sutton in the late 1980s as part of his groundbreaking work in reinforcement learning. Sutton’s contributions laid the foundation for dynamic decision-making in uncertain environments, making TD(0) a cornerstone in the field.
What Is It?
Imagine teaching someone to walk in a dimly lit hallway using a flashlight that only illuminates the next step. TD(0) works in a similar way: it learns step by step, updating its predictions based on immediate feedback from the environment, without needing a full understanding of the entire path (or solution).
This incremental learning approach makes TD(0) highly effective in real-time decision-making tasks.

Why Is It Being Used? What Challenges Are Being Addressed?
TD(0) is widely used because it addresses key challenges in decision-making under uncertainty:
- Online Learning: Updates predictions during the process rather than waiting for the entire episode to finish.
- Balance of Efficiency and Accuracy: Combines the accuracy of Monte Carlo methods with the efficiency of dynamic programming.
- Scalability: Operates effectively even with limited computational resources, making it suitable for large-scale applications.
How Is It Being Used?
The TD(0) algorithm follows these steps:
- Initialisation: Start with an initial value estimate for each state.
- Observation: For each step, observe the current state, action, and resulting reward.
- Update Rule: Apply the TD(0) formula to adjust the value of the current state using the observed reward and the predicted value of the next state.
- Iteration: Repeat the process until the values converge or the task is completed.
This iterative method allows TD(0) to improve predictions incrementally, making it highly efficient in real-world scenarios.
Different Types
TD(0) belongs to the Temporal Difference learning family, which includes:
- TD(λ): A more generalised version that blends TD(0) with Monte Carlo methods for more nuanced learning.
- Q-Learning: Focuses on learning the value of action-state pairs, offering a step further in reinforcement learning.
Key Features
- Bootstrapping: Updates estimates based on other estimates, reducing computational overhead.
- Single-Step Learning: Focuses on immediate transitions, making it suitable for dynamic environments.
- Model-Free Learning: Learns directly from interactions without requiring a predefined model of the environment.
Popular Software and Tools for TD(0)
- OpenAI Gym: Offers diverse environments to test and benchmark TD algorithms.
- RLlib: A scalable reinforcement learning library supporting TD methods.
- TensorFlow and PyTorch: Provide robust frameworks for developing and training TD-based models.
Applications in Australian Governmental Agencies
- Department of Transport, Victoria:
- Use Case: Optimising traffic light sequences.
- Impact: Reduced congestion times by 18% during peak hours.
- Australian Energy Regulator (AER):
- Use Case: Predicting power grid stability.
- Impact: Improved response times to energy fluctuations, preventing outages.
- Australian Taxation Office (ATO):
- Use Case: Fraud detection in real-time tax filings.
- Impact: Identified anomalies with 25% more accuracy, saving millions in revenue.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!