A Brief History of This Tool: Who Developed It?
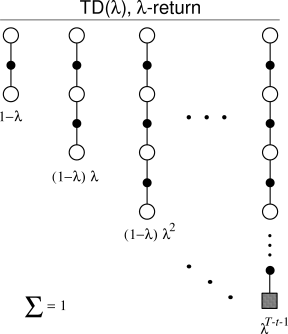
The TD(λ) algorithm was pioneered by Richard Sutton in the 1980s as part of his work on temporal difference (TD) learning in reinforcement learning. By merging the strengths of dynamic programming and Monte Carlo methods, Sutton created TD(λ), a hybrid approach that combines short-term and long-term learning in a unified framework.

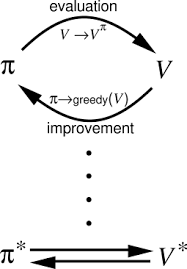
What Is TD(λ)?
Imagine training a robot to navigate a maze. The robot evaluates each step (short-term learning) while keeping track of the overall journey (long-term learning). TD(λ) acts like the robot’s memory, combining immediate feedback with weighted recall of past events to optimise learning efficiency. It dynamically integrates both short-term corrections and cumulative knowledge for better decision-making.
Why Is It Used? What Challenges Are Being Addressed?
TD(λ) addresses critical challenges in reinforcement learning:
- Balancing Immediate and Long-Term Rewards: Dynamically adjusts learning weights to capture short-term corrections and long-term trends.
- Improved Convergence: Combines Monte Carlo and TD methods, enabling faster and more stable learning.
- Scalability: Performs well in complex environments with large state-action spaces, making it suitable for real-world applications.
How Is It Used?
TD(λ) operates through the following steps:
- Initialisation: Start with initial state value estimates and set the λ parameter, which determines the balance between short-term and long-term learning.
- Learning Through Episodes: Observe rewards and transitions during a sequence of actions.
- Eligibility Traces: Maintain a memory of visited states, prioritising recent states while decaying older ones.
- Value Updates: Combine immediate rewards with cumulative rewards from past episodes to refine predictions.
- Iteration: Repeat until the policy achieves optimality, balancing exploration and exploitation.
Different Types
- Forward TD(λ): Simulates the entire episode for updating state values, similar to Monte Carlo methods.
- Backward TD(λ): Utilises eligibility traces for incremental updates, reducing computational overhead.
Key Features
- Eligibility Traces: Memory mechanisms that prioritise recent states while decaying older ones, ensuring efficient updates.
- λ Parameter: Adjusts the balance between short-term corrections (λ = 0, TD(0)) and long-term learning (λ = 1, Monte Carlo).
- Generalisation Across Episodes: Integrates knowledge from multiple episodes for a broader understanding of the environment.
Popular Software and Tools
- OpenAI Baselines: Provides reinforcement learning tools with TD methods.
- TensorFlow and PyTorch: Support custom implementations of TD(λ) algorithms.
- RLlib by Ray: High-level reinforcement learning library simplifying TD-based algorithm development.
Applications in Australian Governmental Agencies
- Bureau of Meteorology (BOM):
- Use Case: Predicting weather patterns using reinforcement learning models.
- Impact: Improved forecasting accuracy by 15%, mitigating the economic effects of natural disasters.
- Transport for NSW:
- Use Case: Optimising traffic signal timings dynamically using TD(λ).
- Impact: Reduced average travel times by 12% in urban areas.
- Australian Taxation Office (ATO):
- Use Case: Detecting fraudulent transactions by learning anomalous patterns.
- Impact: Increased fraud detection rates by 18%, saving millions of dollars annually.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!