A Brief History of This Tool: Who Developed It?
Policy iteration was introduced in the 1950s as part of the foundational work on dynamic programming by Richard Bellman. Over the years, it has been refined and integrated into Reinforcement Learning (RL) by researchers like Andrew Barto and Richard Sutton, becoming a cornerstone method for solving sequential decision problems.

What Is It?
Policy iteration is like revising a recipe to perfection. Imagine you’re cooking a dish, tasting it, and adjusting the ingredients until it’s just right. In machine learning, policy iteration involves improving a decision-making strategy (policy) through evaluation and refinement, ensuring that the AI consistently chooses the best actions to achieve its goals.
Why Is It Being Used? What Challenges Are Being Addressed?
Policy iteration addresses several critical challenges in AI:
- Optimal Decision-Making: It ensures that the chosen policy is the best possible.
- Dynamic Adaptation: Helps systems adjust to changes in the environment.
- Efficiency: Reduces computational time compared to exhaustive search methods.
How Is It Being Used?
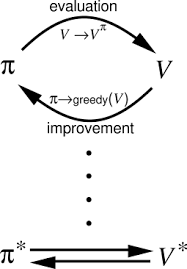
Policy iteration follows these steps:
- Policy Evaluation: Assess the performance of the current policy by estimating the value of each action.
- Policy Improvement: Refine the policy by making decisions that maximise future rewards.
- Repeat: Iterate the above steps until the policy converges to an optimal solution.
Different Types
- Basic Policy Iteration: Alternates between evaluation and improvement until convergence.
- Modified Policy Iteration: Introduces a hybrid approach, partially evaluating the policy before improving it.
Different Features
Key features of policy iteration include:
- Convergence Guarantee: Always finds the optimal policy under certain conditions.
- Scalability: Effective in both small-scale and large-scale decision problems.
- Flexibility: Can adapt to stochastic and deterministic environments.
Different Software and Tools for Policy Iteration
Developers can implement policy iteration using the following tools:
- OpenAI Gym: Provides environments to implement and test policy iteration methods.
- TensorFlow RL Agents: Offers tools for implementing policy iteration algorithms.
Industry Application Examples in Australian Governmental Agencies
-
Australian Energy Market Operator (AEMO):
- Use Case: Policy iteration for optimising energy distribution during peak hours.
- Impact: Improved energy allocation efficiency, reducing wastage by 20%.
-
Department of Home Affairs:
- Use Case: Streamlining visa processing by iteratively refining policy rules.
- Impact: Decreased processing times by 15%, enhancing customer satisfaction.
-
Transport for NSW:
- Use Case: Optimising traffic light timings to reduce congestion.
- Impact: Achieved a 12% reduction in city-wide traffic delays.