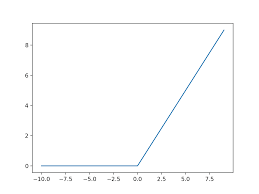
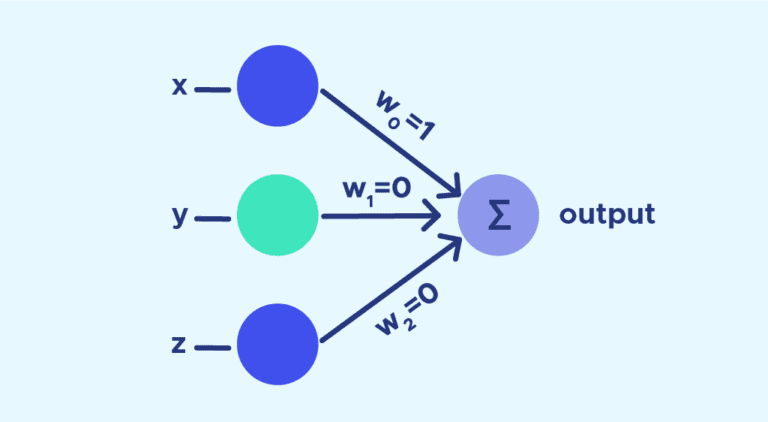
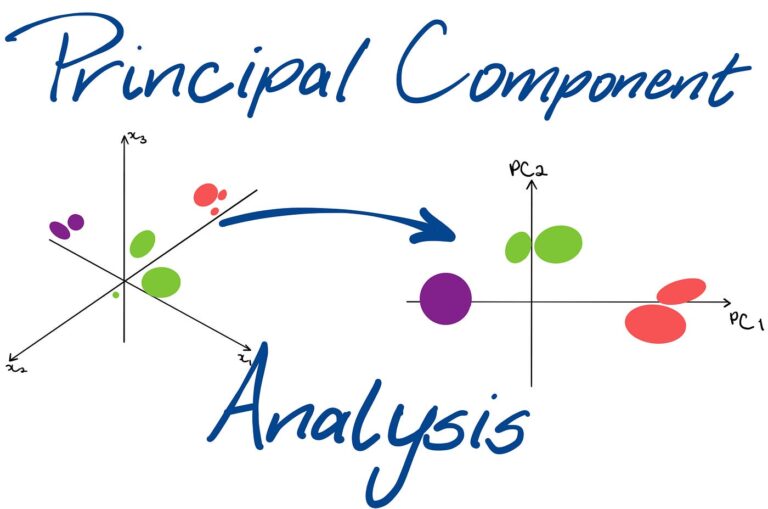
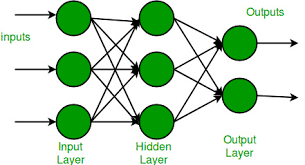
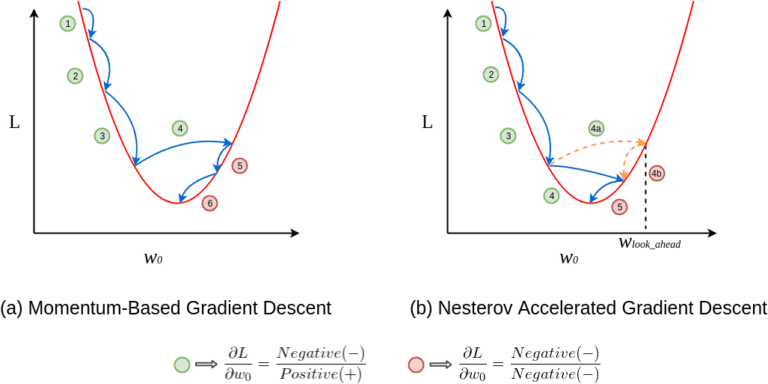
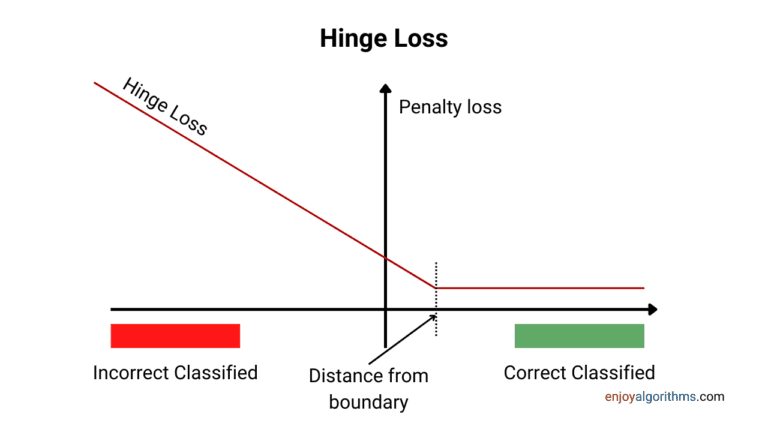
A Very Short Introduction of Rubner-Tavan’s Network
A Brief History: Who Developed It? Rubner-Tavan’s network, introduced in the 1980s by Joseph Rubner and Paul Tavan, emerged from the need to model adaptive neural systems efficiently. This innovation laid the groundwork for advancements in unsupervised learning and data