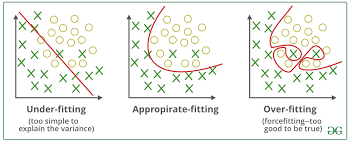
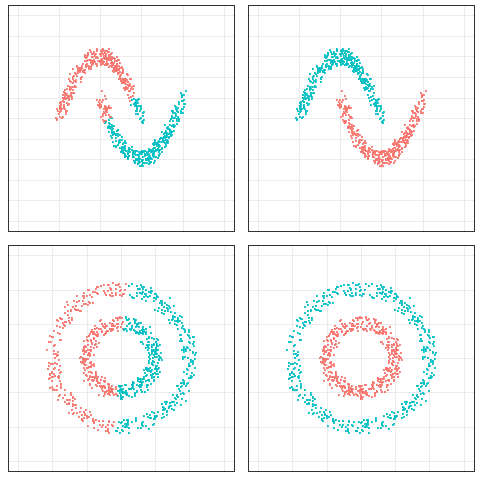
Sanger’s network, introduced by Terence D. Sanger in 1989, is a neural network model designed for online principal component extraction, enhancing feature extraction in unsupervised learning systems.
O’REILLY MEDIA
It simplifies complex datasets by identifying key patterns, making it valuable for dimensionality reduction and data compression. Australian government agencies, such as the Australian Bureau of Statistics and Transport for NSW, utilize Sanger’s network for tasks like census data processing and real-time traffic analysis, respectively. Tools like Scikit-learn and TensorFlow facilitate its implementation in various applications.