A Brief History: Who Developed It?
Random Forest was introduced in 2001 by Leo Breiman and Adele Cutler. Expanding on decision trees and ensemble learning, it became a highly accurate and robust machine learning algorithm. Its development revolutionised predictive modelling, making it a cornerstone of data analysis and artificial intelligence.
What Is Random Forest?
Imagine predicting the weather by consulting multiple experts. Each expert (a decision tree) provides a forecast, and the final prediction is the collective result. Random Forest operates similarly: it combines multiple decision trees to boost accuracy, improve reliability, and minimise overfitting.

Why Is It Used? What Challenges Are Being Addressed?
Random Forest addresses several critical challenges in machine learning:
- Improved Prediction Accuracy: Leverages multiple models for precise and reliable outcomes.
- Robustness Against Overfitting: Reduces the variance and bias typical of single decision trees.
- Versatility for Diverse Data: Excels in handling noisy, incomplete, or unstructured data sets.
Without Random Forest, many predictive models would struggle to manage complex data and inconsistencies effectively.
How Is Random Forest Used?
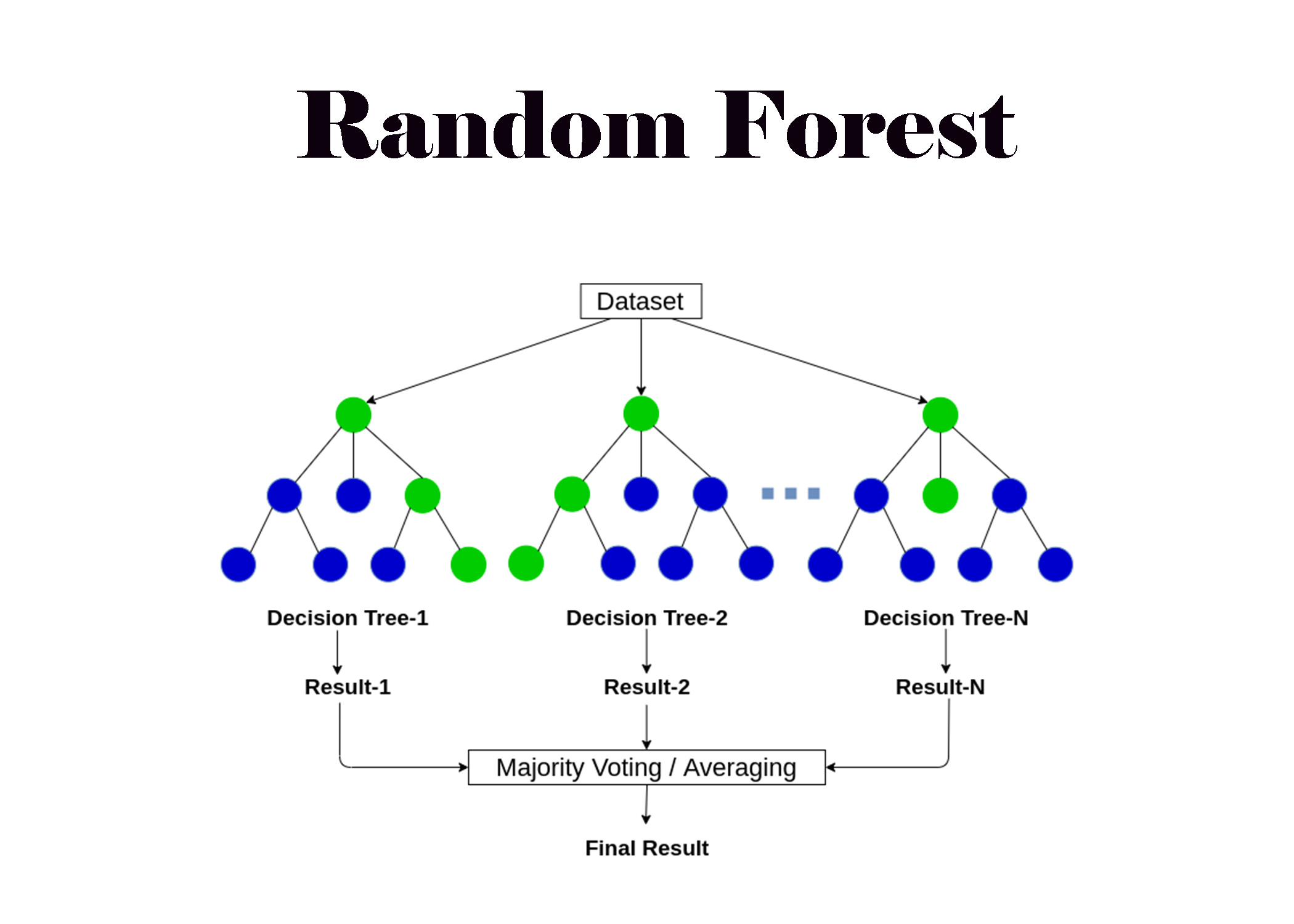
Random Forest operates through the following steps:
- Dataset Splitting: Randomly split the dataset into subsets.
- Tree Training: Train multiple decision trees on these subsets.
- Prediction Aggregation: Aggregate the predictions from all trees using methods such as averaging (for regression) or majority voting (for classification).
Tools such as Scikit-learn provide pre-built functions that simplify the implementation of Random Forest, making it accessible for beginners and experts alike.
Different Types of Random Forest
Random Forest adapts to a variety of machine learning tasks:
- Regression: Predicts continuous variables, such as property values or sales trends.
- Classification: Assigns data into predefined categories, such as spam detection or customer segmentation.
These applications demonstrate its flexibility and relevance across diverse domains.
Key Features of Random Forest
Random Forest offers several unique features:
- Ensemble Learning: Combines multiple models to deliver superior results.
- Feature Importance Analysis: Highlights which variables contribute most to predictions, providing valuable insights.
- High Scalability: Efficiently handles large datasets and complex computations.
Popular Software and Tools for Random Forest
Numerous tools support Random Forest implementations:
- Scikit-learn (Python): Robust solutions for classification and regression tasks.
- XGBoost: Optimised for speed and performance, particularly with large datasets.
- R Libraries: Packages such as
randomForestandcaretoffer comprehensive functionality.
Applications of Random Forest in Australian Governmental Agencies
Random Forest is widely applied across Australian governmental agencies to solve critical challenges:
- Healthcare Forecasting:
- Application: Predicting hospital admission trends to optimise resource allocation.
- Urban Transport Planning:
- Application: Analysing traffic data to improve infrastructure and reduce congestion.
- Environmental Risk Assessment:
- Application: Forecasting air quality to guide proactive policy decisions and ensure public safety.
Conclusion
Random Forest is a transformative machine learning algorithm that combines accuracy, robustness, and versatility. Its ability to process diverse data sets and deliver actionable insights has made it indispensable in fields ranging from healthcare to urban planning. With powerful tools such as Scikit-learn and XGBoost, implementing Random Forest is straightforward, allowing organisations to harness its full potential for solving complex problems.




2 Comments
It’s impressive how Random Forest is used in so many diverse fields, from healthcare to urban transport. As data complexity continues to grow, how do you think Random Forest will evolve to handle even more intricate datasets, particularly in areas like healthcare and environmental forecasting?
Thank you for your question about the future of Random Forest! As you may know, Random Forest belongs to the category of bagging ensemble learning algorithms, which focus on reducing variance and increasing stability. In fact, when comparing bagging, boosting, and stacking, bagging shines in creating robust models, boosting excels at accuracy through bias correction, and stacking takes the crown for adaptability and performance in complex scenarios. Since this is the ultimate goal of these algorithm categories, we can predict their future based on these strengths—although, let’s be honest, we don’t have a magic ball (yet)!
Feel free to explore more blogs on our website about other types of algorithms—we’re always adding exciting insights to help you stay ahead. 😊