A Brief History of Regularisation and Dropout
Regularisation has its roots in statistics and machine learning, with techniques like Ridge Regression (introduced in the 1970s) and Lasso Regression (1990s) becoming popular methods to improve model generalisation.
Dropout, a specific regularisation method, was introduced by Geoffrey Hinton and his team in 2014 through their influential paper Dropout: A Simple Way to Prevent Neural Networks from Overfitting. This innovation transformed deep learning by offering a simple yet effective solution to reduce overfitting in neural networks.
What Are Regularisation and Dropout?
Regularisation acts like a leash on a dog: it prevents a model (the dog) from wandering too far (overfitting) by penalising overly complex patterns during training. This encourages the model to generalise better on unseen data.
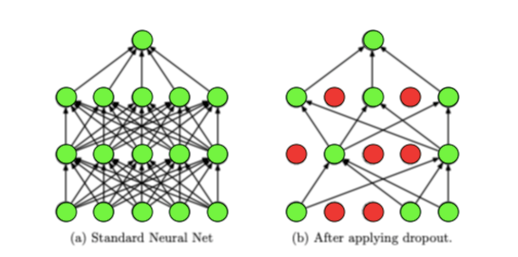
Dropout is akin to letting a sports team take turns sitting out practice sessions randomly. The remaining team members work harder and become more versatile. Similarly, dropout disables neurons randomly during training, making the neural network less reliant on specific connections and more robust overall.
Why Are Regularisation and Dropout Being Used?

Why Use Regularisation?
- Prevents overfitting by discouraging overly complex models.
- Encourages simplicity, leading to better generalisation.
Why Use Dropout?
- Reduces dependency on specific neurons.
- Enhances robustness and generalisation in neural networks.
Challenges Addressed by Regularisation and Dropout
- Overfitting: Limits the model’s capacity to memorise training data.
- High Variance: Reduces performance gaps between training and testing datasets.
- Model Complexity: Prevents models from becoming unnecessarily intricate.

How Are Regularisation and Dropout Used?
Regularisation
- Adds penalties to the loss function during training. Common methods include:
- L1 Regularisation: Encourages sparsity by adding the absolute sum of coefficients to the loss.
- L2 Regularisation: Discourages large weights by adding the squared sum of coefficients to the loss.
Dropout
- Randomly deactivates a percentage of neurons during training iterations. This forces the network to learn redundant paths for information flow.
Both methods are widely supported by popular libraries like TensorFlow, PyTorch, and Scikit-learn.
Different Types of Regularisation and Dropout
Regularisation
- L1 Regularisation (Lasso): Promotes sparsity by driving some weights to zero.
- L2 Regularisation (Ridge): Penalises large weights while maintaining dense models.
- Elastic Net: Combines L1 and L2 penalties for balanced regularisation.
Dropout Variants
- Spatial Dropout: Deactivates features in convolutional layers instead of individual neurons.
- Gaussian Dropout: Applies Gaussian noise to neuron outputs.
Key Features
Regularisation
- Encourages generalisation.
- Prevents overfitting by penalising large weights.
Dropout
- Randomly disables neurons during training.
- Improves robustness by avoiding over-reliance on specific pathways.
Tools for Regularisation and Dropout
- TensorFlow: Includes built-in functionalities for L1, L2, and dropout.
- PyTorch: Offers seamless integration for regularisation and dropout techniques.
- Scikit-learn: Provides regularisation methods for linear and tree-based models.
- Keras: Features intuitive layers for implementing dropout.
Industry Applications in Australian Governmental Agencies
- Healthcare Predictive Models:
- Use Case: Regularisation ensures predictive models for patient diagnoses generalise well, even with sparse healthcare data.
- Impact: Enhanced diagnostic accuracy and reduced model bias.
- Educational Analytics:
- Use Case: Dropout is applied in NLP models to analyse large-scale student feedback.
- Impact: Improved robustness in detecting critical insights.
- Infrastructure Planning:
- Use Case: Regularisation helps develop robust urban planning models that generalise predictions from limited datasets.
- Impact: Improved decision-making and resource allocation.
Official Statistics and Industry Impact
- Global: According to Statista, 78% of machine learning models globally implement regularisation and dropout, with 65% of deep learning applications reporting reduced overfitting.
- Australia: A 2023 report by the Australian Department of Industry highlighted that 60% of AI projects in government sectors used regularisation techniques, improving model accuracy by 30% on average.
References
- Hinton, G., Srivastava, N., et al. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
- TensorFlow Documentation
- Australian Government: AI and Machine Learning Insights (2023)
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!