A Brief History: Who Developed Regularization?
Regularization, a key technique in machine learning, originated from statistics and mathematics to address overfitting in predictive models. Popularized in the 1980s, it became central to regression analysis and neural networks. Researchers like Andrew Ng introduced methods such as L1 Regularization (Lasso) and L2 Regularization (Ridge), which are now widely used in machine learning workflows to enhance model performance.
What Is Regularization?
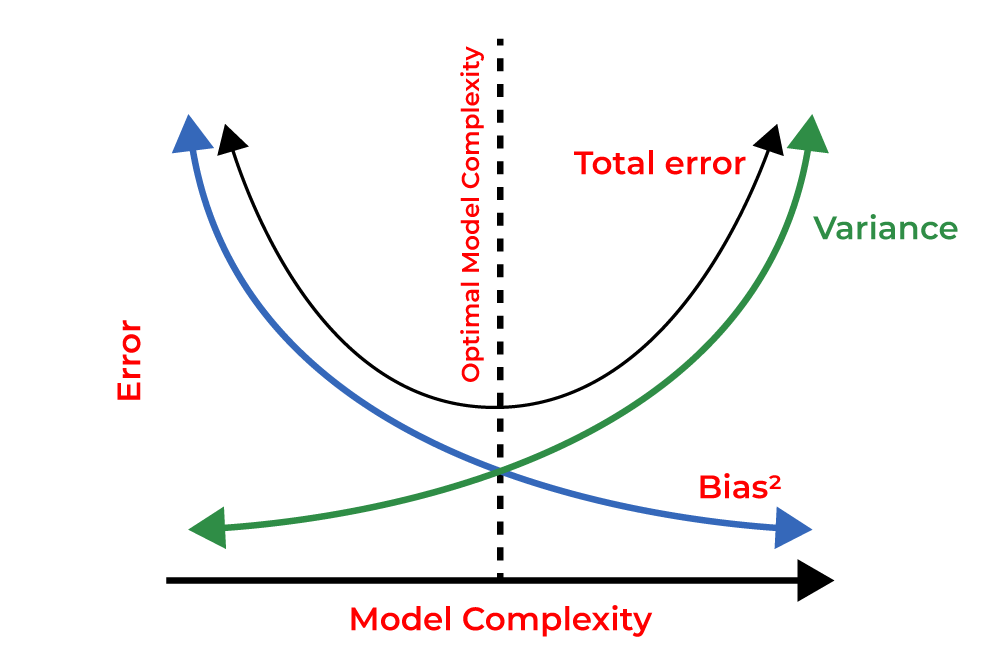
Regularization is a technique that reduces overfitting by introducing penalties for complex models. It helps a model generalize better by discouraging reliance on unnecessary features. Regularization is like marathon training. If you only train on a flat track (memorizing data), you won’t be prepared for varied terrains (new data). Adding resistance, like running with weights (regularization), builds adaptability and robustness, just as it strengthens models to handle unseen data.
Why Is It Used? What Challenges Does It Address?
Regularization solves key challenges in machine learning models:
- Overfitting Prevention: Stops the model from memorizing noise in training data.
- Model Simplification: Focuses on the most relevant features, reducing unnecessary complexity.
- Generalization: Improves performance on unseen datasets, enabling reliable predictions.
Without regularization, models often perform well on training data but fail to deliver accurate results in real-world applications.
How Is It Used?
- Introduce Regularization Terms: Add a penalty term to the loss function.
- Select Regularization Type: Choose methods such as L1, L2, or Dropout.
- Optimize: Minimize the loss function using gradient descent algorithms to improve classification accuracy.
Different Types
- L1 Regularization (Lasso): Encourages sparsity by shrinking irrelevant feature weights to zero.
- L2 Regularization (Ridge): Prevents large weight values, smoothing model predictions.
- Elastic Net: Combines L1 and L2 to balance feature selection and model stability.
- Dropout: Randomly deactivates neurons during training to reduce dependency on specific nodes in neural networks.
Key Features
- Simplicity: Reduces model complexity by minimizing unnecessary parameters.
- Flexibility: Works across various machine learning tasks, including regression and classification.
- Scalability: Adapts well to both small and large datasets.
Software and Tools Supporting Regularization
- Python Libraries:
- Scikit-learn: Implements L1 and L2 regularization for regression and classification.
- TensorFlowand PyTorch: Offer advanced methods like dropout and custom penalties.
- XGBoostand LightGBM: Include built-in regularization techniques for gradient boosting algorithms.
- Platforms: Google Colab and Jupyter Notebooks are ideal for testing and visualization.
3 Industry Application Examples in Australian Governmental Agencies
- Healthcare (Department of Health):
- Application: Predicting hospital readmission rates from patient data.
- Use of Regularization: Ensures focus on key predictors like age and treatment history, avoiding overfitting to irrelevant details.
- Environmental Management (Department of Agriculture, Water, and the Environment):
- Application: Forecasting water quality across regions.
- Use of Regularization: Reduces the influence of outliers, ensuring the model generalizes across varying conditions.
- Public Policy (Australian Bureau of Statistics):
- Application: Modeling population growth trends by state.
- Use of Regularization: Balances complexity to avoid overfitting while accounting for diverse demographic patterns.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!