The Origins of KD-Trees: Revolutionising Multidimensional Data Processing
KD-Trees, introduced in 1975 by Jon Louis Bentley, transformed how multidimensional data is processed. Designed for optimising nearest-neighbour searches, KD-Trees remain a cornerstone in computational geometry and data science.
What Are KD-Trees? Simplifying Nearest-Neighbour Searches
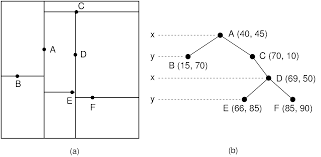
Think of a KD-Tree as a digital library catalogue: it systematically organises data points across multiple dimensions, enabling quick searches. Each node represents a data point, while branches partition the dataset into smaller, more navigable sections.

Why KD-Trees Are Essential: Efficiency, Scalability, and Cost Reduction
KD-Trees address three key challenges:
- Efficiency: Perform nearest-neighbour searches quickly.
- Scalability: Handle large multidimensional datasets seamlessly.
- Cost Reduction: Minimise computational resource usage in data-heavy operations.
How KD-Trees Work: From Data Partitioning to Query Optimisation
KD-Trees operate through these mechanisms:
- Data Partitioning: Recursively splits data along dimensions.
- Query Optimisation: Limits the search space for efficient nearest-neighbour or range queries.
- Dynamic Data Handling: Supports the addition and deletion of data points while maintaining utility over time.
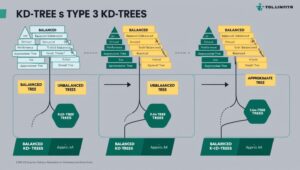
Exploring Types of KD-Trees: Balanced, Unbalanced, and Approximate
- Balanced KD-Trees: Optimised for uniform datasets.
- Unbalanced KD-Trees: Designed for skewed data distributions.
- Approximate KD-Trees: Trade precision for faster queries, especially in high-dimensional spaces.
Features of KD-Trees: Space Division, Adaptability, and Flexibility
KD-Trees are defined by their core features:
- Space Division: Partitions data into smaller, manageable regions.
- Dimensional Adaptability: Works effectively with datasets containing various attributes.
- Real-Time Flexibility: Enables updates and scaling without performance loss.
Top Tools for KD-Trees: Scikit-Learn, FLANN, and More
Several tools provide robust KD-Tree functionality:
- Scikit-learn: A leading Python library for KD-Tree implementation.
- FLANN: Specialises in high-speed approximate nearest-neighbour searches.
- MATLAB: Offers KD-Tree tools for engineering and scientific applications.
- NumPy: Simplifies basic KD-Tree operations.
KD-Trees in Australia: Applications Across Government Agencies
KD-Trees are applied in various Australian industries:
- Geoscience Australia: Uses KD-Trees for geological data analysis and mapping.
- Bureau of Meteorology (BOM): Employs KD-Trees for climate pattern analysis and clustering.
- Department of Infrastructure: Optimises urban planning by analysing spatial datasets.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!