A Brief History: Who Developed Early Stopping?
Early stopping emerged in the field of neural networks and statistical learning during the late 20th century. It was developed to address the challenge of overfitting in iterative optimization algorithms. Though not attributed to a single inventor, it gained prominence in the 1990s with advancements in machine learning. Today, early stopping is a fundamental technique in machine learning workflows, helping to enhance both model efficiency and generalization.
What Is Early Stopping?
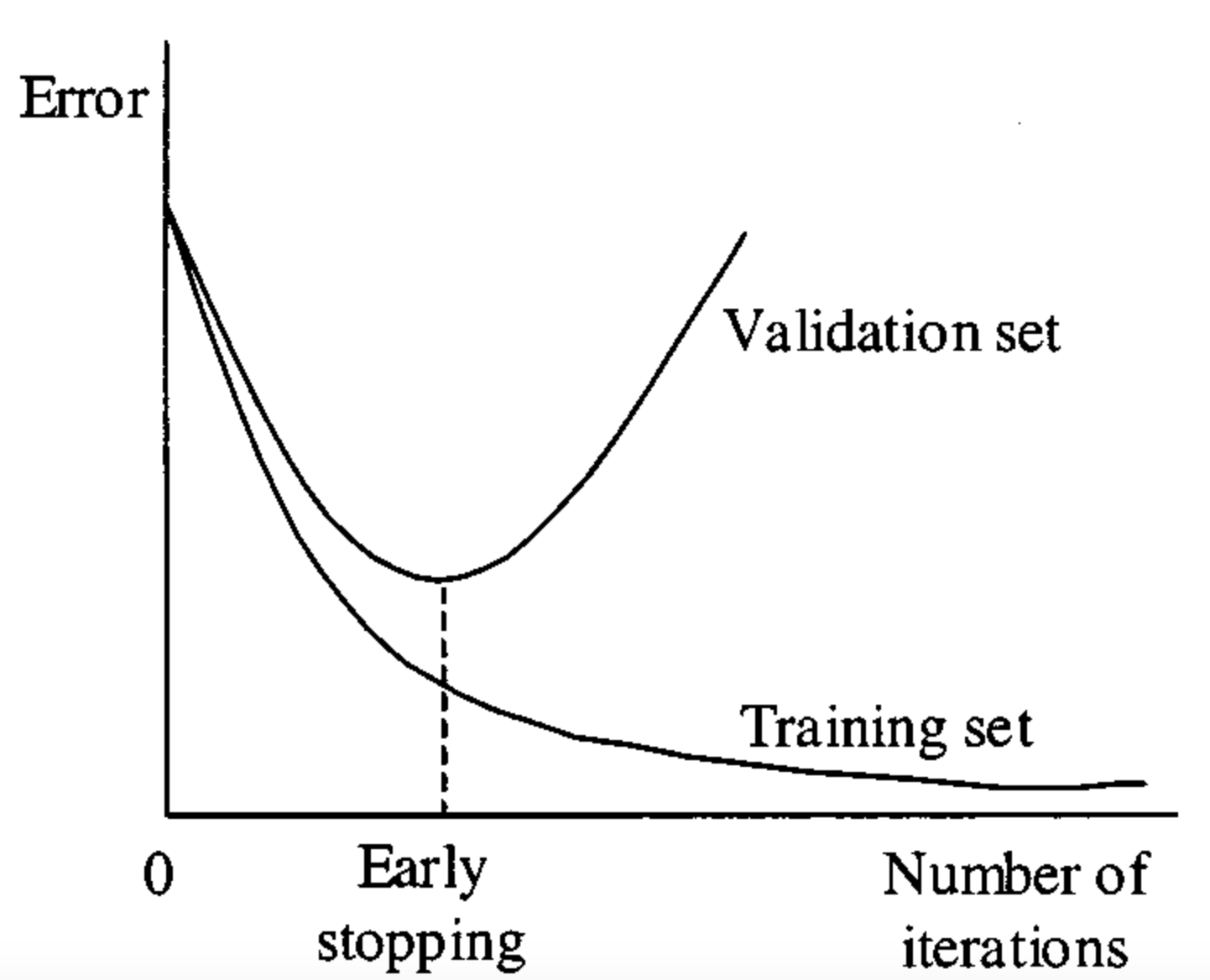
Early stopping is a regularization technique used during model training to halt the process when performance on a validation dataset stops improving. This prevents the model from overfitting the training data and ensures better predictions on unseen datasets.
It acts like a traffic signal for model training, indicating when to pause to avoid going too far and compromising the model’s stability.

Why Is It Used? What Challenges Does It Address?
Early stopping addresses several challenges in machine learning:
- Prevents Overfitting: Stops training before the model memorizes noise or irrelevant patterns in the data.
- Reduces Computational Costs: Saves time and resources by halting training when no further improvements are observed.
- Improves Generalization: Increases accuracy on real-world datasets by focusing on meaningful patterns.
Without early stopping, models may overtrain, leading to high complexity, reduced generalization, and unnecessary computational overhead.
How Is It Used?
- Monitor Validation Metrics: Track metrics like validation accuracy or loss during training.
- Set a Patience Parameter: Define the number of epochs to wait for improvement after the last best metric.
- Stop Training: End the training process when validation performance fails to improve consistently.
Different Types
- Standard Early Stopping: Halts training based on a specific metric, such as validation loss or accuracy.
- Patience-Based Early Stopping: Allows a set number of epochs for improvement before stopping.
- Custom Early Stopping: Implements user-defined criteria tailored to specific training objectives.
Key Features
- Adaptable: Works with various machine learning algorithms, including neural networks and gradient boosting.
- Resource-Efficient: Reduces computational waste by halting unnecessary training iterations.
- Performance-Driven: Focuses on maximizing model accuracy while avoiding overfitting.
Software and Tools Supporting Early Stopping
- Python Libraries:
- Keras/TensorFlow: Provide built-in early stopping callbacks like EarlyStopping for easy implementation.
- PyTorch: Offers customizable solutions through packages like torch.optim.lr_scheduler.
- Scikit-learn: Supports early stopping in models such as gradient boosting (early_stopping=True).
- Platforms: Interactive environments like Google Colab and Jupyter Notebooks enable testing and visualization of early stopping.
3 Industry Application Examples in Australian Governmental Agencies
- Healthcare (Department of Health):
- Application: Training predictive models for disease diagnosis and risk assessment.
- Use of Early Stopping: Prevents overfitting in models trained on limited healthcare datasets, ensuring reliable outcomes.
- Environmental Management (Department of Agriculture, Water, and the Environment):
- Application: Forecasting weather patterns for resource management.
- Use of Early Stopping: Saves computation time while maintaining robust predictions for environmental changes.
- Public Policy (Australian Bureau of Statistics):
- Application: Modeling economic trends and population forecasts.
- Use of Early Stopping: Balances computational efficiency with model accuracy in long-term predictive analyses.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!