The Evolution of Momentum Optimisation: From Basics to Nesterov Acceleration
Momentum optimisation was introduced in the 1980s: it aimed to improve the convergence speed of gradient descent. In 1983, Yurii Nesterov developed Nesterov Accelerated Gradient (NAG), refining momentum for better gradient updates and faster optimisation in machine learning.
What Are Momentum and Nesterov Momentum? A Practical Guide
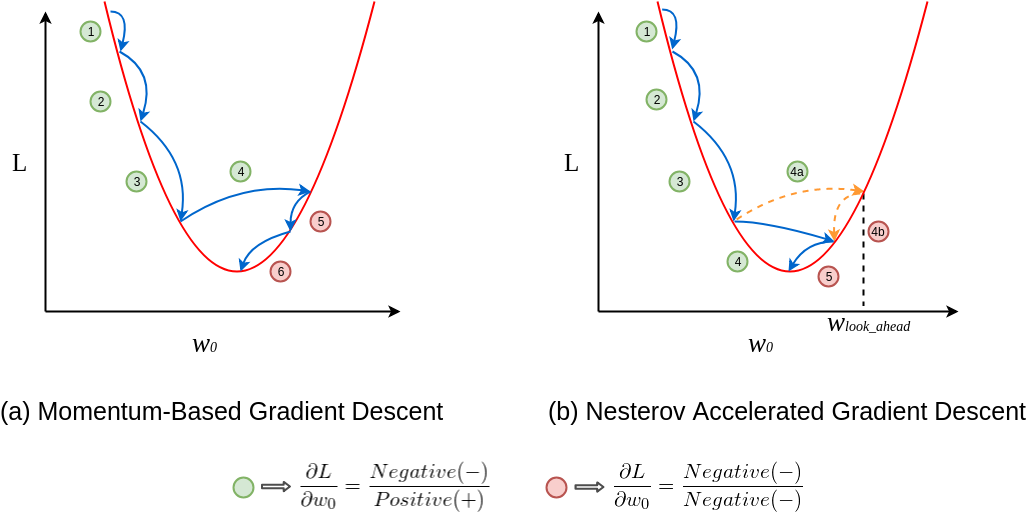
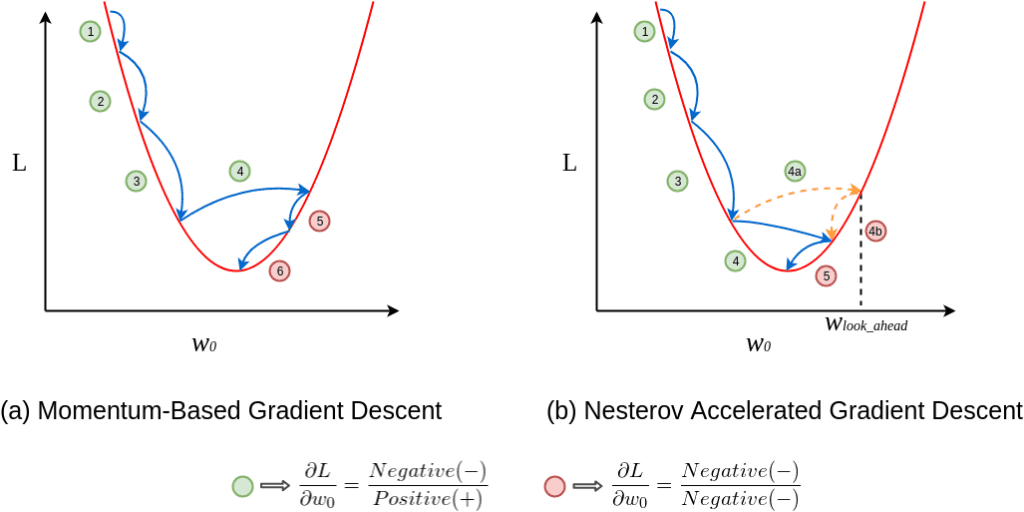
Think of riding a bike downhill: the faster you go, the more momentum helps you overcome bumps and obstacles. Momentum optimisation works similarly, smoothing out gradient updates to speed up convergence. Nesterov Momentum improves this by predicting the next gradient direction, and provides more precise updates.
Why Momentum Optimisation Is Essential in Machine Learning
Momentum and Nesterov Momentum address the following challenges:
- Slow Convergence: They accelerate optimisation in flat areas of the loss function.
- Oscillations: Momentum reduces fluctuations in steep valleys, stabilizing the optimisation process.
- Local Minima: These methods help escape shallow local minima, leading to more accurate solutions.
How Momentum and Nesterov Momentum Enhance Model Training
These techniques are integral during model training:
- Momentum: Adds a fraction of the previous gradient to the current one for smoother updates.
- Nesterov Momentum: Uses the current gradient to “look ahead,” ensuring more efficient and accurate updates.
Momentum vs Nesterov Momentum: Understanding Their Differences
Two primary variations exist:
-
Standard Momentum: Accumulates gradients for faster convergence.
- Nesterov Momentum: Combines gradient accumulation with predictive adjustment for greater precision.
Key Features of Momentum Optimisation Techniques
Key features include:
- Acceleration: Speeds up training by reducing slow gradients.
- Stability: Minimises oscillations in the optimization path.
- Precision: Nesterov Momentum anticipates the next step, and improves update accuracy.
Best Tools for Implementing Momentum and Nesterov Momentum
These methods are supported by various frameworks:
-
- TensorFlow/Keras: Built-in support for SGD with momentum and Nesterov options.
- PyTorch: Implements both techniques in torch.optim.SGD.
- Scikit-learn: Includes basic momentum capabilities for optimisation.
Real-Life Applications of Momentum Optimisation in Australia

- Healthcare Analytics (AIHW): Momentum optimises machine learning models
- Transport Planning (Transport for NSW): Nesterov Momentum accelerates training of traffic flow prediction models.
- Environmental Forecasting (CSIRO): Enhances AI-driven climate prediction models through efficient optimisation techniques.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!