A Brief History of Value Iteration
Value iteration was introduced by Richard Bellman during the 1950s as part of his groundbreaking work on optimal control theory. This revolutionary algorithm became a cornerstone of dynamic programming, forming the foundation of modern reinforcement learning methods.
What Is Value Iteration?
Imagine refining a rough gemstone step by step until it shines brilliantly. Value iteration works similarly: it iteratively optimises the “value” of each state in a decision-making process, clarifying the most rewarding actions at every step.

Why Is Value Iteration Used? What Challenges Does It Address?
Value iteration is a powerful tool for solving complex decision problems because it:
- Derives Optimal Policies: Identifies the best strategy for decision-making in Markov Decision Processes (MDPs).
- Simplifies Computation: Offers a clear and systematic approach to problem-solving.
- Adapts to Scale: Works effectively for both small and large-scale problems in structured environments.
How Is Value Iteration Used?
The process involves the following steps:
- Initialisation: Start with arbitrary value estimates for all states.
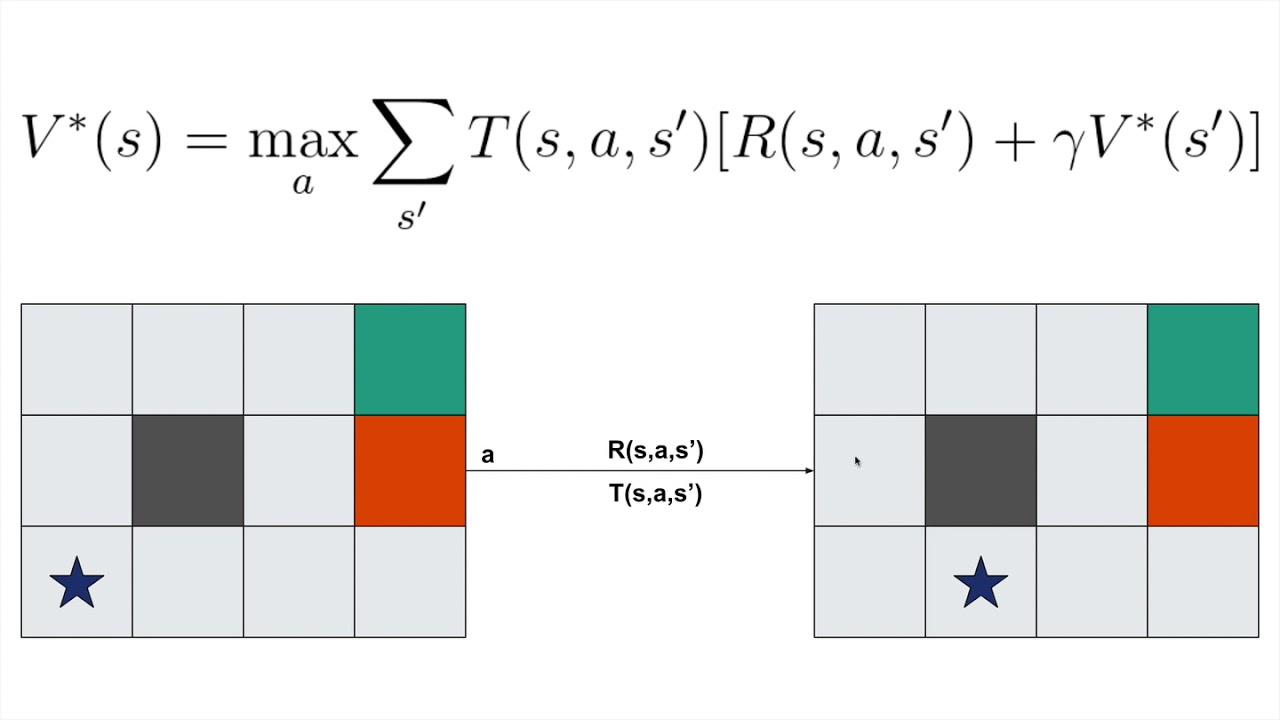
- Value Update: Use the Bellman equation to refine each state’s value based on potential rewards and future values.
- Policy Extraction: Determine the best action for each state by maximising the expected value.
- Iteration: Repeat steps 2 and 3 until the values converge to a stable solution.
This iterative method ensures an optimal policy is derived for decision-making.
Different Types of Value Iteration
Value iteration has several variants to address different needs:
- Classic Value Iteration: Updates all states in each iteration.
- Asynchronous Value Iteration: Focuses on subsets of states in each iteration for faster convergence.
- Approximate Value Iteration: Uses function approximations for large or complex problems.
Key Features of Value Iteration
Value iteration is known for its:
- Guaranteed Convergence: Always finds the optimal policy for finite MDPs.
- Efficiency: Reduces computational demands by refining values iteratively.
- Scalability: Works for problems of varying sizes and complexities, from small grids to complex real-world systems.
Popular Tools and Software
Implementing value iteration is made easier with tools such as:
- OpenAI Gym: Provides environments for testing and implementing reinforcement learning algorithms.
- RLlib: A reinforcement learning library that supports value iteration methods.
- MATLAB/Octave: Ideal for mathematical modelling and implementing algorithms like value iteration.
Applications in Australian Governmental Agencies
Value iteration has proven its utility across Australian sectors:
- Australian Bureau of Statistics (ABS):
- Use Case: Optimising survey distribution policies.
- Impact: Increased survey response rates by 15%, enhancing data collection efficiency.
- Department of Health:
- Use Case: Allocating resources to healthcare facilities.
- Impact: Reduced patient wait times by 12% through better equipment distribution.
- Transport for Victoria:
- Use Case: Traffic signal optimisation for public transport corridors.
- Impact: Reduced travel times by 20% during peak hours.
Conclusion
Value iteration is a transformative algorithm that continues to shape decision-making processes in industries worldwide. Its ability to iteratively refine decisions makes it invaluable for reinforcement learning, resource allocation, and policy optimisation. With tools like OpenAI Gym and MATLAB, implementing value iteration is accessible for solving even the most complex decision problems.
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!