A Brief History of Batch Normalisation
Batch normalisation was introduced by Sergey Ioffe and Christian Szegedy in their seminal 2015 paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. This breakthrough technique revolutionised deep learning by addressing challenges like slow training and instability in neural networks, marking a significant milestone in AI research.
What is Batch Normalisation?
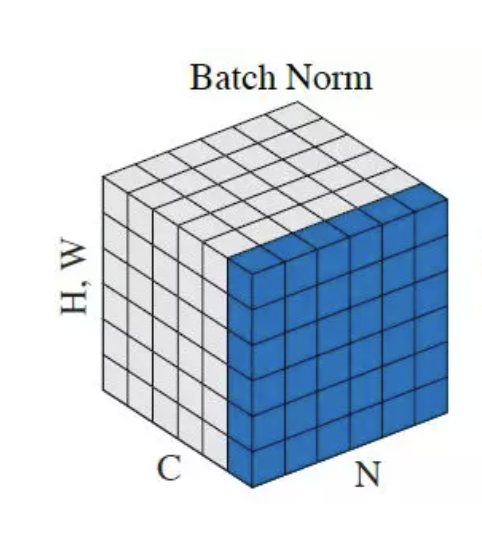
Batch normalisation acts as a quality control inspector for neural networks, ensuring inputs to each layer are consistent. By standardising data within each batch during training, it stabilises the optimisation process and enables models to converge faster.
Think of it as recalibrating ingredients in a recipe to ensure a dish turns out perfectly every time, regardless of variations in initial measurements.

Why Is Batch Normalisation Being Used? What Challenges Does It Address?
Why use Batch Normalisation?
- Faster Training: Reduces the number of epochs required for model convergence.
- Stabilises Learning: Mitigates shifts in data distributions across layers, ensuring smoother training.
- Improves Robustness: Reduces sensitivity to poor weight initialisation and enables higher learning rates.
Challenges addressed:
- Internal Covariate Shift: Prevents disruptions caused by changing data distributions during training.
- Overfitting: Acts as an implicit regulariser, often reducing the need for dropout.
- Exploding/Vanishing Gradients: Stabilises gradient flow, making it effective for deeper neural networks.
How Is Batch Normalisation Used?
Batch normalisation is applied between the layers of a neural network and consists of the following steps:
- Normalise Inputs: Standardise inputs to have a mean of zero and variance of one.
- Scale and Shift: Introduce trainable parameters that scale and shift the normalised data, allowing the network to adapt and retain its representational power.
This method is seamlessly integrated into popular deep learning frameworks such as TensorFlow, PyTorch, and Keras.
Different Types of Batch Normalisation
- Batch Normalisation: Normalises across mini-batches of data.
- Layer Normalisation: Normalises across all features of an individual data point.
- Instance Normalisation: Normalises each instance in a batch, commonly used in style transfer tasks.
- Group Normalisation: Normalises within feature groups, suitable for smaller batch sizes.
Features of Batch Normalisation
- Batch-Level Normalisation: Keeps inputs consistent across training iterations.
- Learnable Parameters: Trainable scaling and shifting parameters allow the network to recover the original distribution if necessary.
- Versatility: Applicable to diverse architectures, including convolutional and recurrent networks.
Software and Tools Supporting Batch Normalisation
- TensorFlow: Provides
BatchNormalizationlayers with adjustable parameters. - PyTorch: Includes
BatchNormlayers for 1D, 2D, and 3D inputs. - Keras: Simplifies implementation through its
BatchNormalizationlayer. - MXNet: Supports batch normalisation for large-scale applications.
Industry Applications in Australian Governmental Agencies
- Healthcare AI: Enhances disease detection by improving the stability of deep learning models trained on medical imaging datasets.
- Education Analytics: Optimises models analysing student performance and feedback trends.
- Environmental Monitoring: Boosts the accuracy of climate prediction models by ensuring stable training across varied datasets.
Official Statistics and Industry Impact
- Global: As of 2023, 82% of deep learning models utilised batch normalisation, reducing training time by 30% on average (Statista).
- Australia: A 2023 report by the Australian Department of Industry highlighted that 68% of AI projects adopted batch normalisation, improving model stability and cutting computational costs by 25%.
References
- Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
- TensorFlow Documentation
- Australian Government: AI Applications Report (2023).
How interested are you in uncovering even more about this topic? Our next article dives deeper into [insert next topic], unravelling insights you won’t want to miss. Stay curious and take the next step with us!