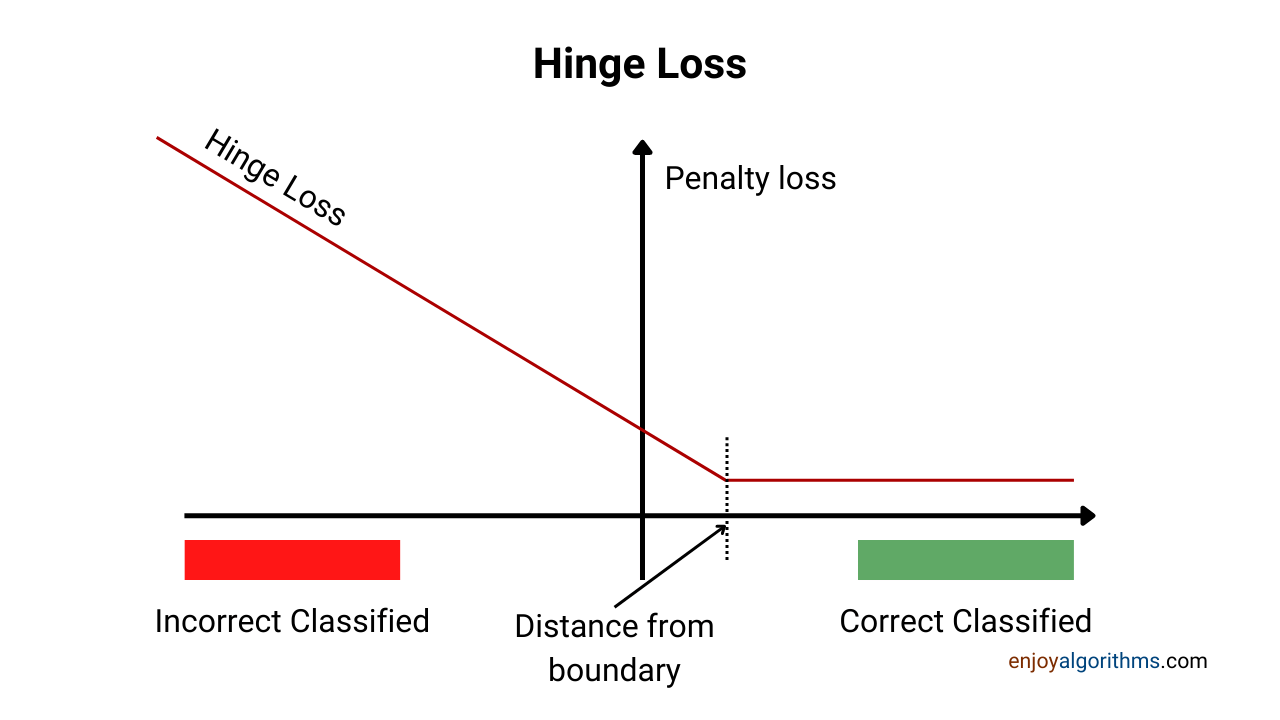
The Hinge cost function, introduced in the 1990s, is vital for improving classification models by maximising margins and penalising misclassifications. This blog explores its history, features, tools, and applications in Australian industries like healthcare and transportation.