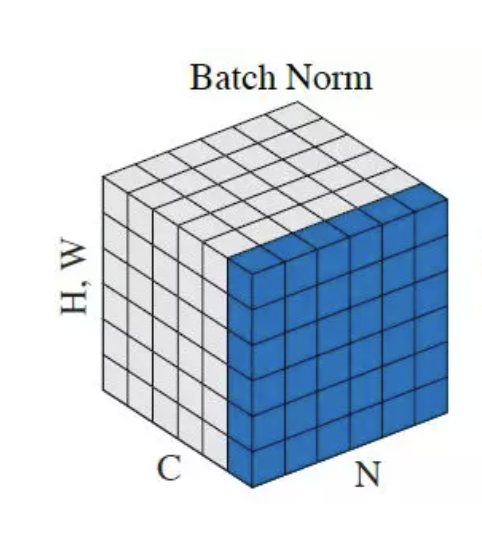
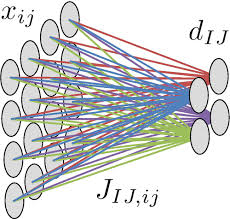
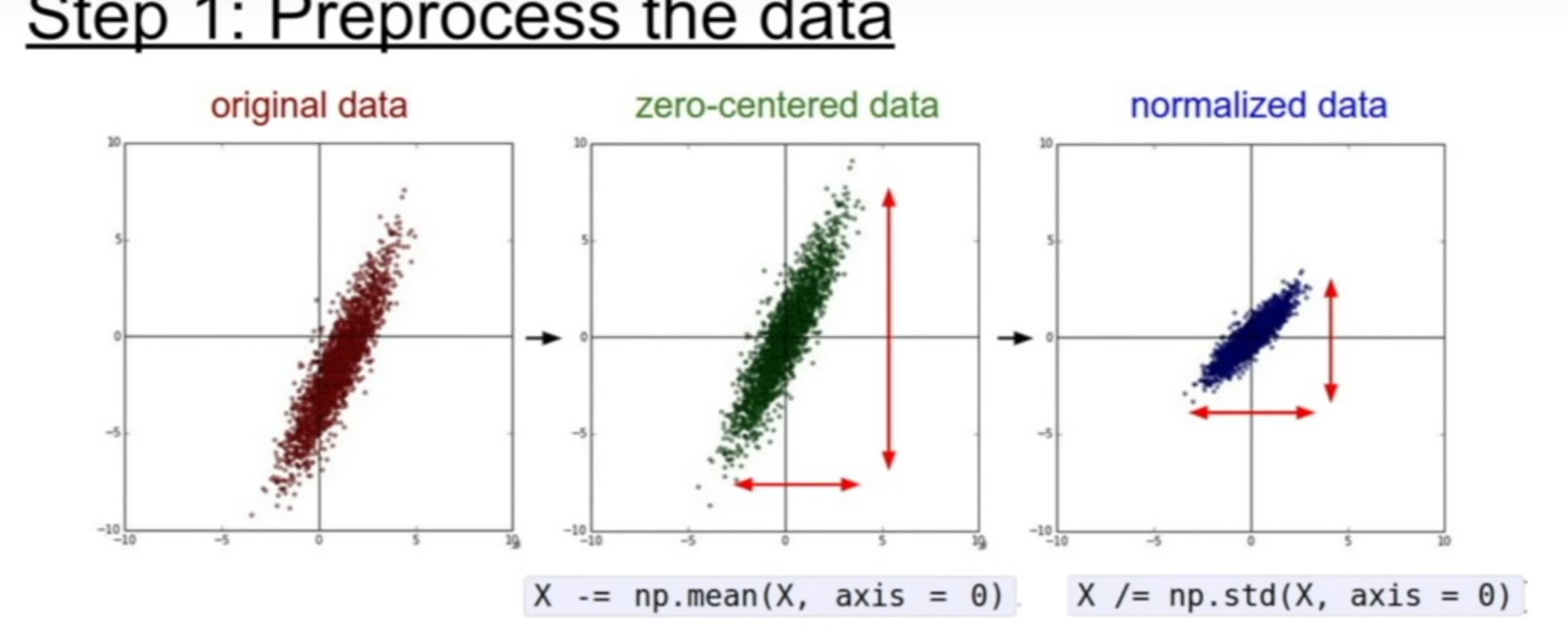
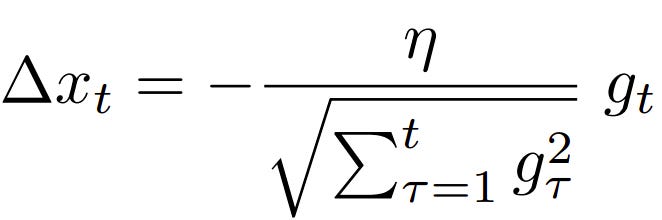Batch normalisation is a game-changer in deep learning, enabling faster training, stabilising neural networks, and improving overall model performance. It has become a vital tool in AI applications across industries, including healthcare, education, and environmental science.